Interpreting physics in video world models
Authors: Sonia Joseph, Quentin Garrido, Randall Balestriero, Matthew Kowal, Thomas Fel, Shahab Bakhtiari, Blake Richards, and Mike Rabbat.
Work done at Meta Superintelligence Labs.
Full preprint: https://arxiv.org/abs/2602.07050
This post walks through our main findings and intuition behind our interpretability study of physics representations in video world models.

Why this work matters
- Physics reasoning turns on at a specific depth. Video models exhibit a clear phase transition– the Physics Emergence Zone– where physical understanding rapidly appears, with the strongest representations in the middle layers.
- Steering only works in high dimensions. Physics variables are implemented as population codes spread across many feature directions, so causal control requires coordinated changes rather than a single vector shift.
- The code is strikingly brain-like. Direction-selective neurons tile the full angular space, forming a circular population code reminiscent of findings in motion neuroscience.
- World models may become auditable systems. Identifying where and how physical variables are implemented points toward interpretable, controllable models for robotics and scientific simulation.
In one of the first interpretability studies of physics in video models, we set out to ask a simple question: where does physical reasoning actually live inside the network? The answer turns out to be a clear structural transition inside the JEPA video encoder.
We identify a Physics Emergence Zone roughly one-third through the network where spatiotemporal processing reorganizes and physics-relevant representations crystallize. The strongest task-relevant representations appear in the middle layers before becoming more entangled toward the output.
Drilling down into specific physical variables, we find that motion direction is the key signal associated with this transition. At the Physics Emergence Zone, MLP neurons form an almost perfect circular population code for direction, reminiscent of motion-tuned neurons observed in biological vision. In feature space, however, direction occupies a high-dimensional subspace composed of many orthogonal components, meaning that steering direction requires coordinated changes across dozens of features.
These findings provide a concrete mechanistic picture of where physical reasoning lives inside video world models, while also pointing toward a broader possibility: world models whose internal physical latents can be interpreted and audited, laying groundwork for safer robotics, physical AI, and data-driven scientific simulators.
Introduction
Despite rapid progress in video modeling, it remains unclear whether--and how--video world models represent physical information internally. Prior work has largely addressed this question indirectly, evaluating downstream performance on physics benchmarks while treating the model as a black box (Yi et al., 2020; Garrido et al., 2025; Motamed et al., 2025). As a result, we lack answers to fundamental representational questions, such as:
- Where in the network physical information is constructed (if at all)?
- How it is organized across layers and patches?
- What geometric form do these representations take?
In this post, we operationalize “physics-like reasoning” primarily as coherent object dynamics over time (e.g., tracking motion and detecting violations of physical continuity), and we focus on representations inside video encoders.
Imagine a ball rolling across a floor. A student in introductory physics might reason about this by computing velocity from position over time, and acceleration from velocity. This chain of reasoning is hierarchical and compositional, with simple abstractions composing higher-order ones. A video model could, in principle, reason this way: explicitly representing Newtonian variables and propagating them across layers.
Alternatively, a model might reach correct physical judgments without relying on compact, well-factored variables. Some theories in motion neuroscience propose that velocity perception emerges from distributed representations that gradually become global and position-invariant, rather than from explicit symbolic derivation (Pasternak & Tadin, 2020; Born & Bradley, 2005).
Understanding the internal organization of physical models has three major implications beyond benchmark accuracy:
- Learning scientific simulators from data
A model that infers stable physical structure from unlabeled video could aid scientific modeling in regimes where analytic simulators are incomplete or unavailable, including climate systems, fluid dynamics, and materials science. While we are far from full scientific simulators, interpretable latent variables may form a foundation for such systems by providing insight into the governing dynamics learned from data.
- Auditing the reliability of robotics and physical agents.
Understanding the internal organization of video encoders would be useful in auditing the safety and reliability of physical actors, including for hallucinations, sycophancy, and deception. Consider the somewhat science-fiction example of a household robot tasked with doing the dishes. While programmed to do dishes, the robot might in its free time begin doing something nefarious in the real world—such as scheming how to use the cleaning materials underneath the sink to make bombs (similar to the plot of Service Model, in which a seemingly harmless butler robot is sent to the interpretability department to diagnose why he unexpectedly killed his master with a shaving razor!).
Physical errors by real-world agents would have more immediate and potentially deadly effects than their digital counterparts, and interpretability would provide an additional layer of safety when auditing these systems. Representations that correlate with “nefarious” real-world activity may show up in early layers of the video encoder; however, compared to language interpretability, we still have a limited understanding of what happens in the video portion of a robotics model.
- Informing cognitive science and neuroscience.
Finally, interpretability of video models informs a longstanding debate in cognitive science and neuroscience about how humans reason about the physical world. Does physical reasoning rely on compact, reusable latent states– often described as an intuitive physics engine (McCloskey, 1983; Battaglia et al., 2013; Ullman et al., 2017)– or instead arise from heuristic, "hacky," task-specific reasoning (Siegler, 1976; Vasta & Liben, 1996; Davis et al., 2017)? Or something in between? Given that collecting data in behavioral and neuroscience studies can be noisy and costly, video world models act as a substrate for an artificial "brain," whose results can guide and de-risk real-world experiments (Richards, 2019).
In the rest of this post, we look at the emergence of physical representations inside video encoders and connect our findings to these three directions: scientific modeling, system reliability, and theories of physical reasoning.
Intuitive physics
Physical reasoning in video world models is not formally defined, but broadly refers to the ability to infer object properties, dynamics, and interactions, including object permanence, shape constancy, and spatiotemporal continuity (Xue et al., 2023). We have an "intuitive" sense that objects don't spontaneously appear or disappear, change shape, or reverse their trajectory. This understanding of physics is often referred to as intuitive physics, or a "commonsense" understanding of how humans expect the physical world to behave.
We begin with an intuitive physics task as a coarse yet informative proxy for physical reasoning more generally. Specifically, we use the IntPhys dataset to design a task where the model has to distinguish between matched possible and impossible physics pairs (see below).

The Physics Emergence Zone is where physical understanding emerges one-third into the video encoder
We train linear probes at every layer of the three V-JEPA 2 video encoders (for now, we ignore the V-JEPA predictor), and VideoMAE v2 G to do binary classification between possible and impossible pairs.
Surprisingly, the emergence pattern of performance on this task is highly consistent across model sizes and architectures (figure below, left). This consistency was one of the first hints that we were observing something structural rather than dataset-specific. We corroborate the result using a more expressive attentive-MLP probe (figure below, right) to rule out the possibility that the pattern is an artifact of linear probing.
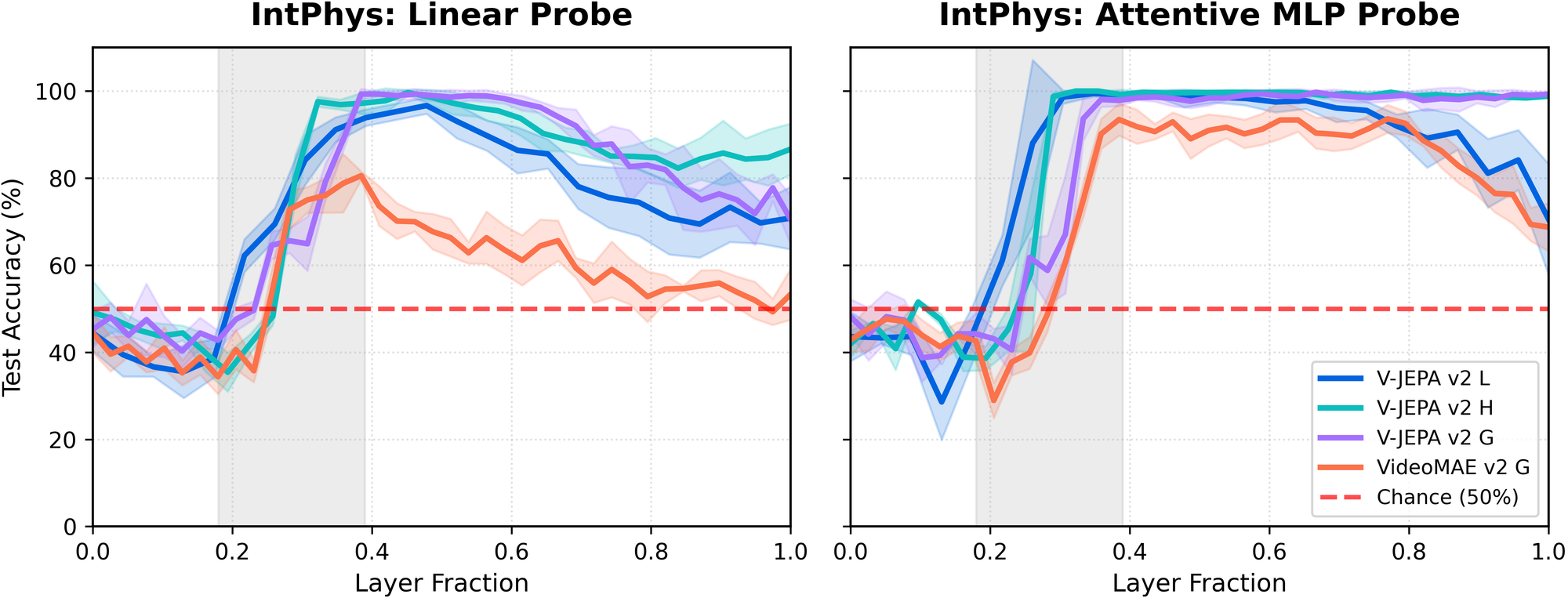
The best intuitive physics representations are in the middle layers.
One immediate and practically relevant insight is that the strongest representations for this task are not found at the end of the network, but in the middle layers. This is contrary to the common intuition that “deeper is always better,” and suggests a more nuanced view of where task-relevant information lives in deep video models. This finding echoes past results showing that intermediate representations can outperform final layers for certain tasks in contrastively trained vision–language models (Bolya et al., 2025).
Practically, this suggests that downstream systems using video embeddings may benefit from tapping intermediate layers rather than defaulting to the final representation. For example, recent work using JEPA embeddings to improve the physical plausibility of video generation could benefit from this insight (Yuan et al., 2025).
We further test this directly and find that intermediate representations improve V-JEPA 2 predictor performance on a violation-of-expectation physics task that measures next-frame plausibility (figure below).
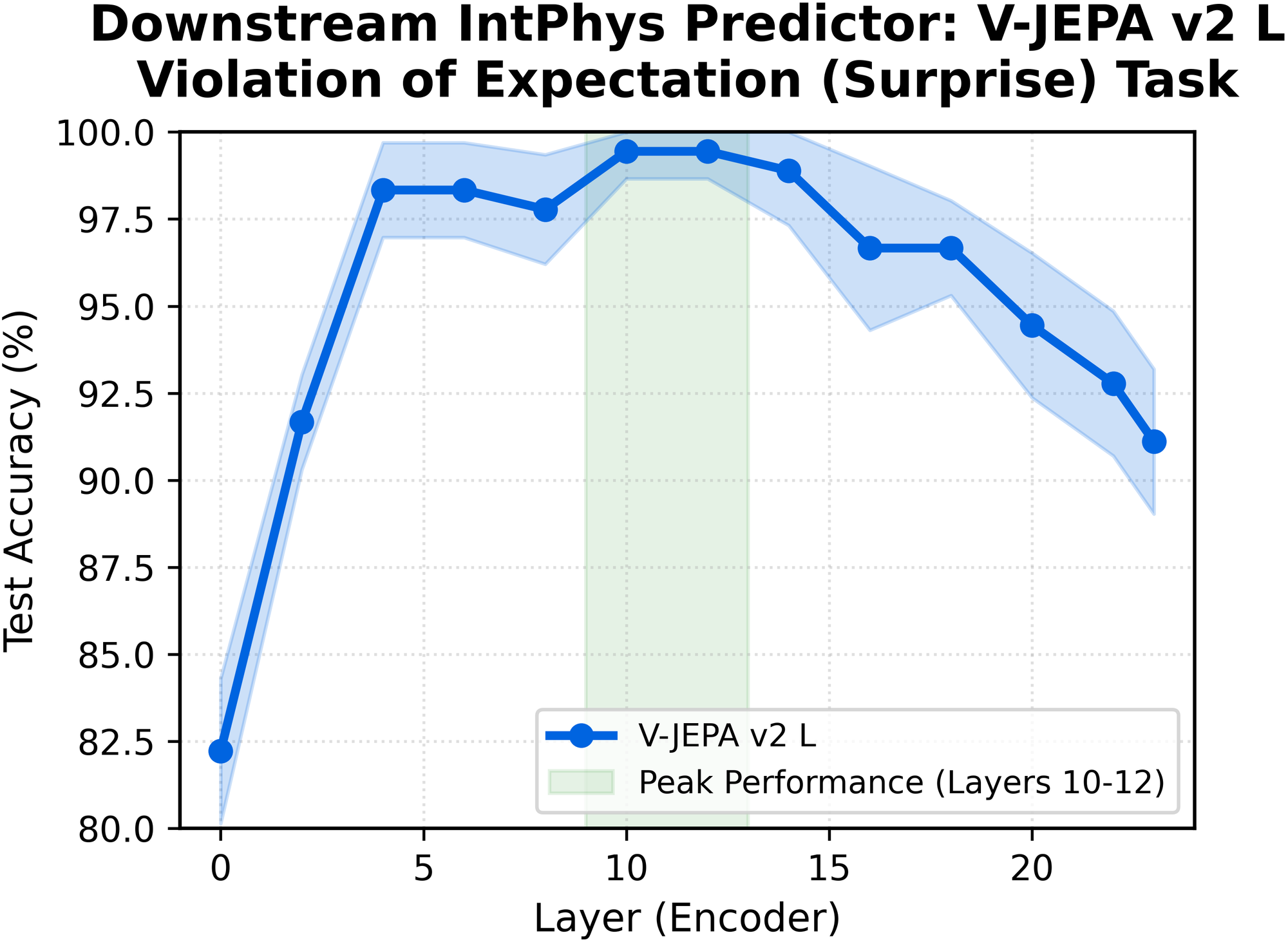
Future interpretability work will be needed to understand why this mid-layer peak occurs. One possible explanation is feature binding, where physics-relevant features are most tightly associated with their corresponding objects at this stage (Treisman, 1996).
In later layers, optimization for masked spatiotemporal prediction in latent space may take precedence over preserving object-level structure, leading to more entangled (“smeared”) representations.
Cartesian and polar representations in the network
The intuitive physics task provides a holistic behavioral signal: it tells us whether the model can distinguish between physically possible and impossible events, but not which specific variables drive this judgment. To move beyond this coarse signal, we next examine explicit physical variables that admit clear ground truth.
This decomposition lets us ask how physics-related information is represented internally. Is the network using Newtonian abstractions, like acceleration and velocity? If so, are they encoded in a Cartesian coordinate system, a polar one, or some kind of alien coordinate system that does not correspond cleanly to how humans reason about physics?
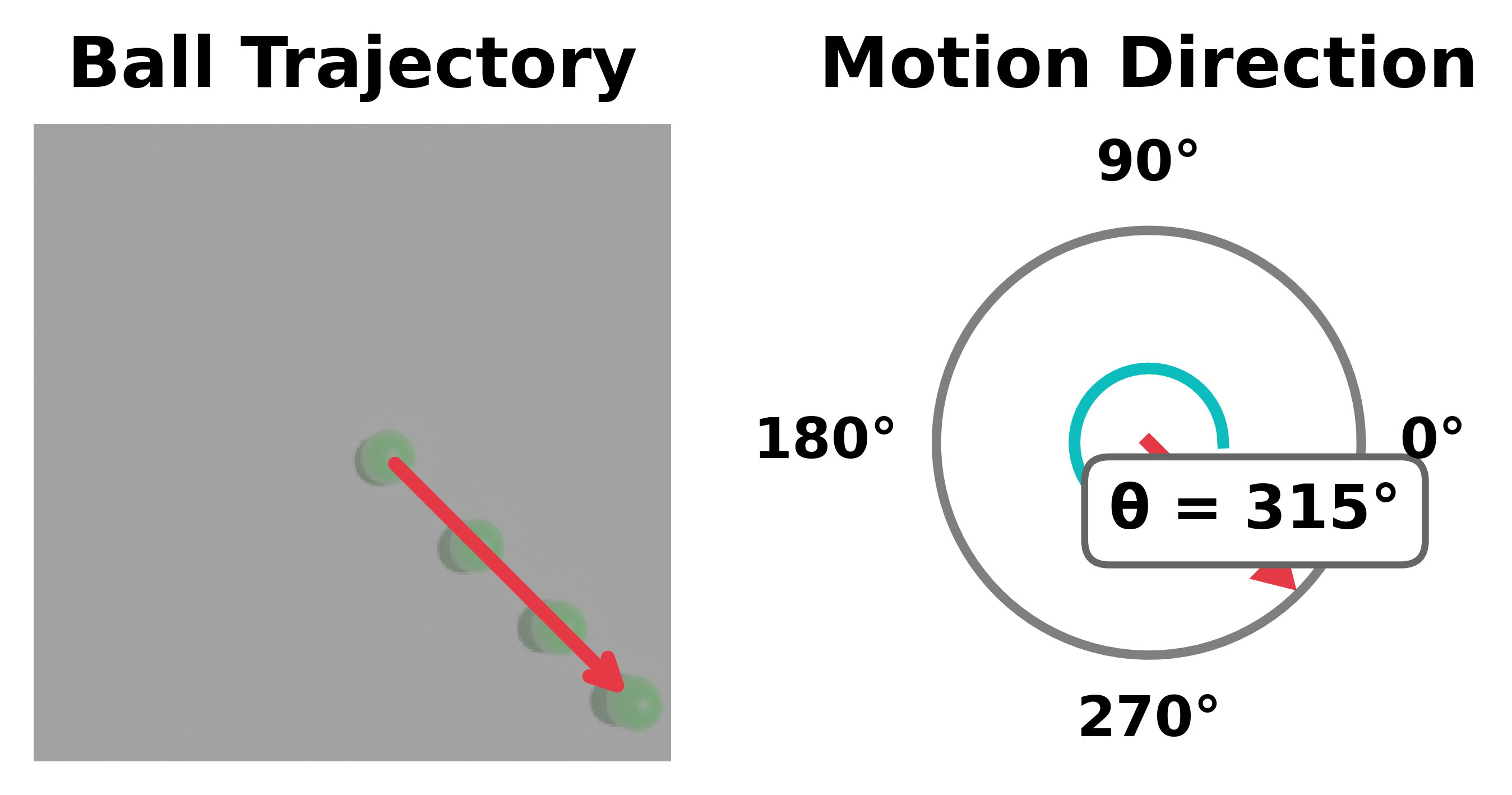
To probe these questions, we generate synthetic single-ball videos using the Kubric simulator (Greff et al., 2022) with controlled motion parameters (figure below). The ball follows straight-line trajectories under either constant velocity or externally induced acceleration, with all other factors held fixed. Ground-truth motion variables are measured in pixels per frame, enabling targeted probing of velocity and acceleration in both Cartesian and polar parameterizations (e.g., (vx, vy) versus (r, θ))
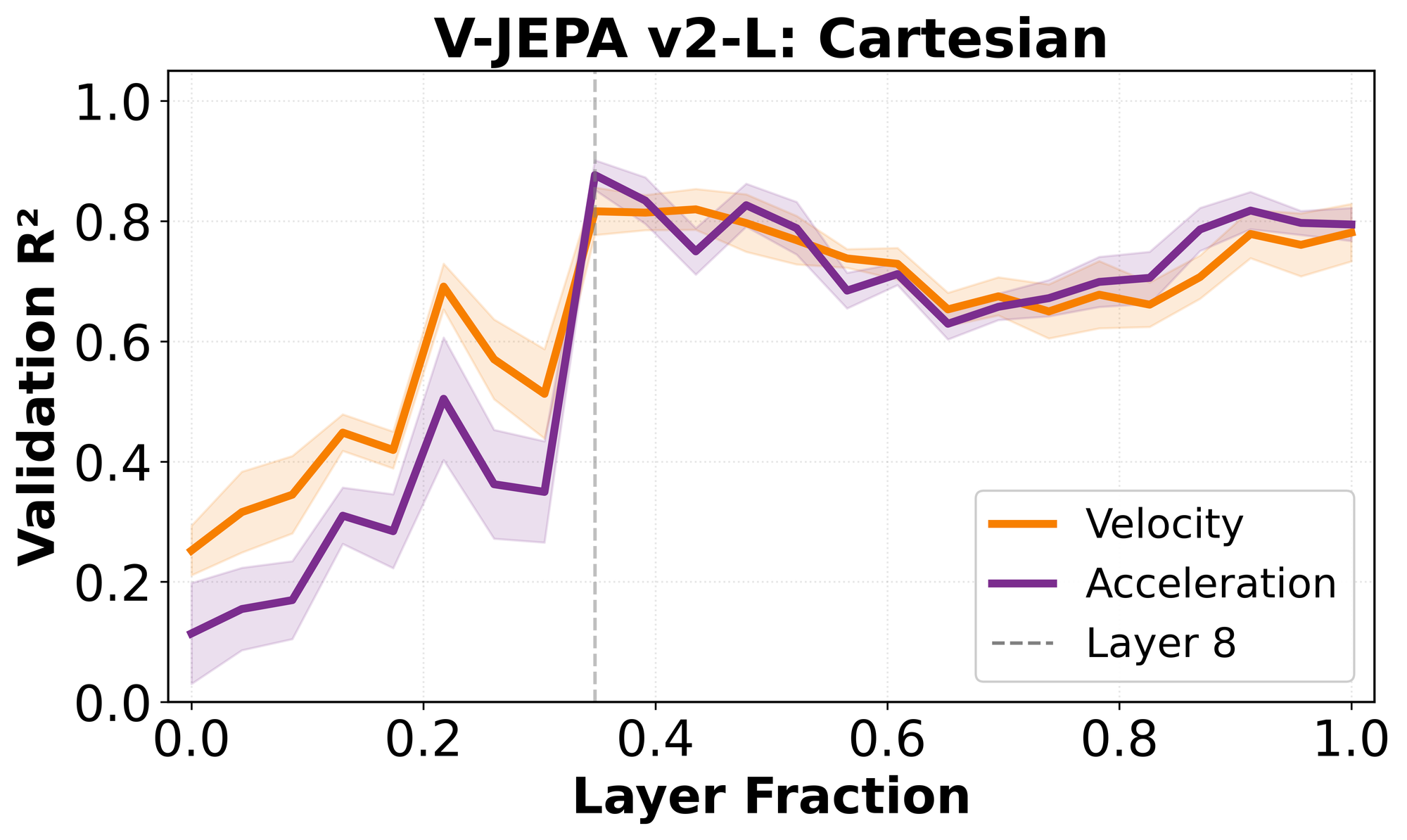
Velocity and acceleration emerge almost simultaneously
When decoding the Cartesian representation of velocity (vx, vy) and acceleration (ax, ay) with linear probes at each layer of the video encoder, we discover that the two quantities become available almost simultaneously.
This result is somewhat surprising. One might expect acceleration to be derived from velocity, as in Newtonian reasoning, or at least to emerge later in the network. Instead, both variables follow the same emergence pattern as the intuitive physics task, becoming strongly decodable around the Physics Emergence Zone:
Direction (θ) emerges in the Physics Emergence Zone; speed emerges early
Cartesian variables entangle motion magnitude and direction, making it unclear which component drives the transition we observe. To disentangle these factors, we reparameterize motion in polar coordinates.
Under this parameterization, speed and acceleration magnitude are available from very early layers, while direction (θ) becomes reliably decodable only at the Physics Emergence Zone.
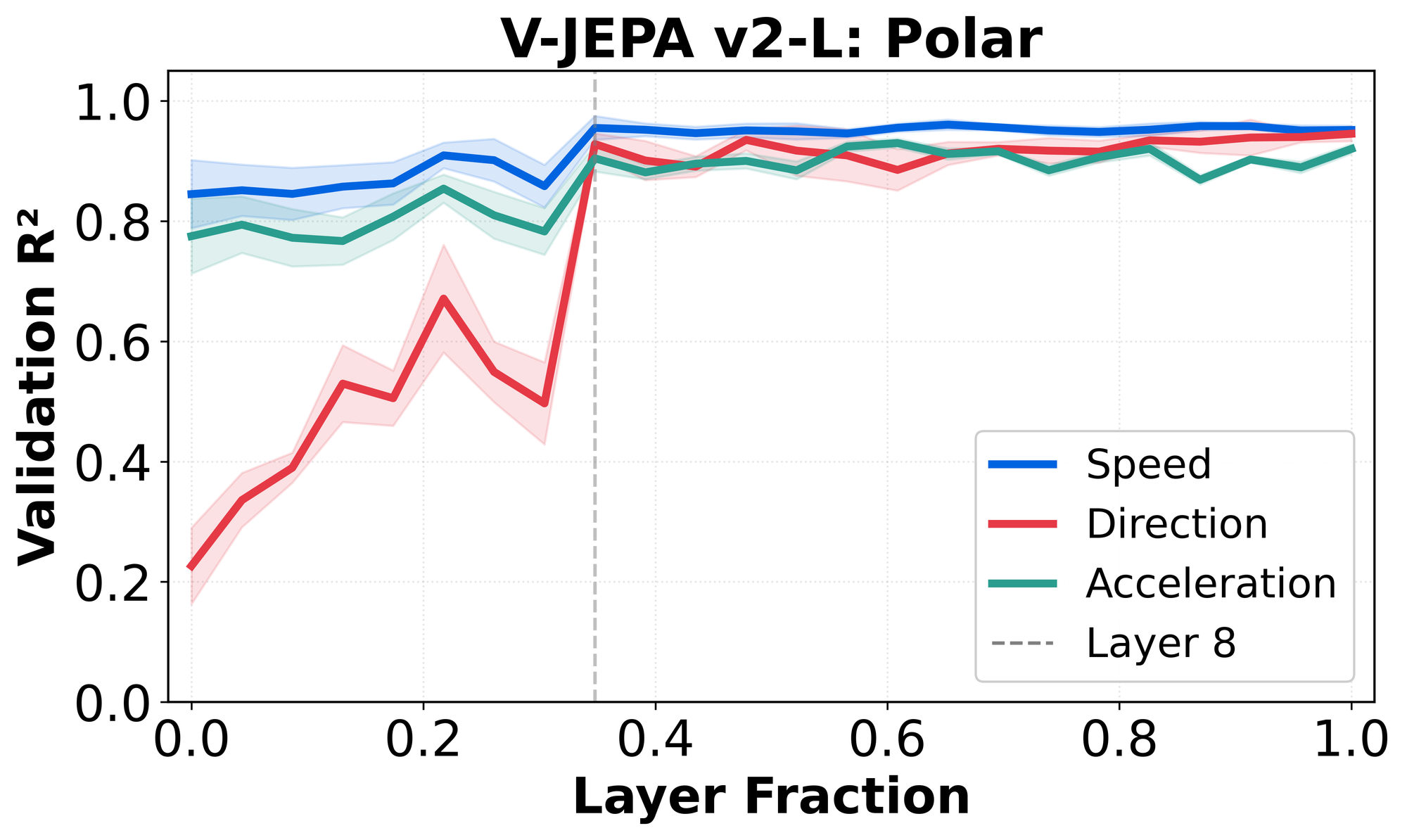
The pattern shows that the Physics Emergence Zone is most strongly associated with the emergence of motion direction, rather than with motion magnitude.
Interestingly, the early availability of speed and later emergence of direction echo the motion-processing hierarchy in biological vision, in which speed-sensitive motion energy appears early, while higher-order pooling gives rise to position-invariant direction selectivity at later stages (Pasternak & Tadin, 2020; Born & Bradley, 2005).
We also observe the same direction-emergence pattern on the multi-object CLEVRER dataset (Yi et al., 2020). When we train object-specific probes for polar direction, availability increases in the Physics Emergence Zone, peaks in the middle layers, and then plateaus.
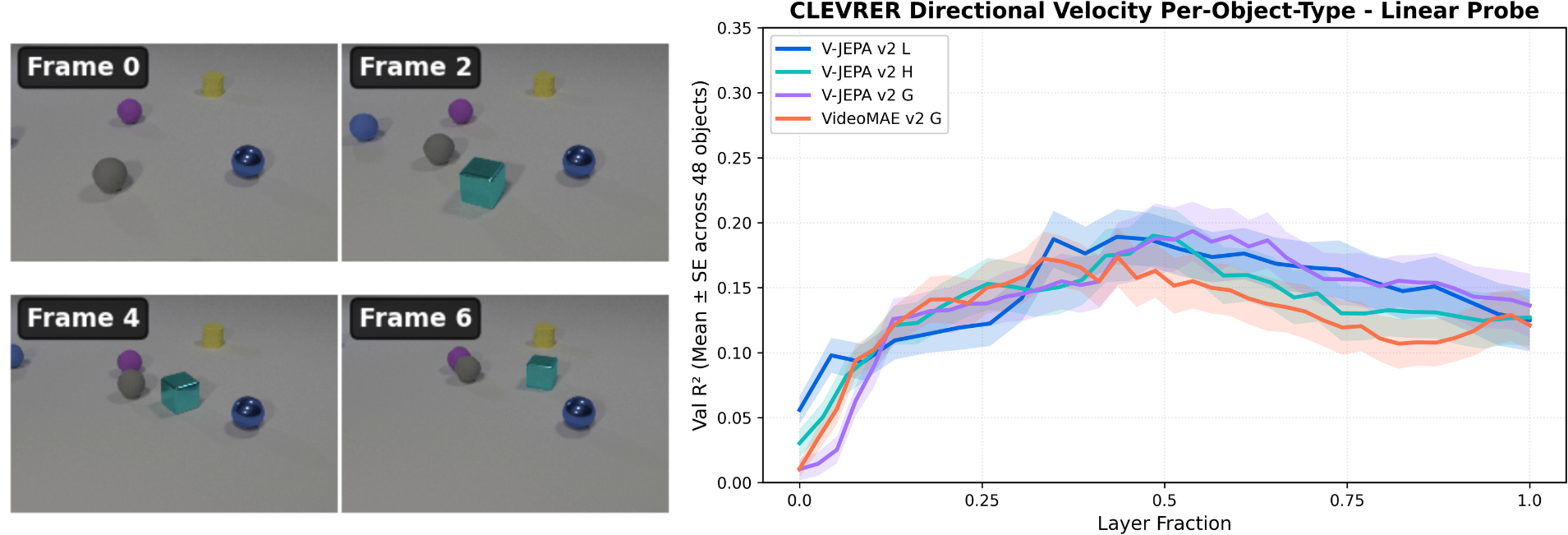
This suggests that direction emergence is not limited to simple single-object motion, but generalizes to more complex scenes.
Direction and intuitive physics occupy near-orthogonal subspaces.
We have shown that the intuitive physics and direction tasks co-emerge in the Physics Emergence Zone, but their relationship in representation space remains unclear. Are the two capabilities actually related internally, or do they merely become accessible at the same depth?
We consider three hypotheses:
- The two tasks may also reflect a generic depth-dependent effect of the model that applies to all tasks.
- The tasks share a representational feature space (e.g., direction is reused compositionally for intuitive physics judgments).
- The tasks rely on shared circuit-level computation without sharing latent representations.
The answer helps clarify whether video encoders behave more like reusable physics engines with shared latents, or like systems with task-specific subspaces.
We test each hypothesis in the next section:
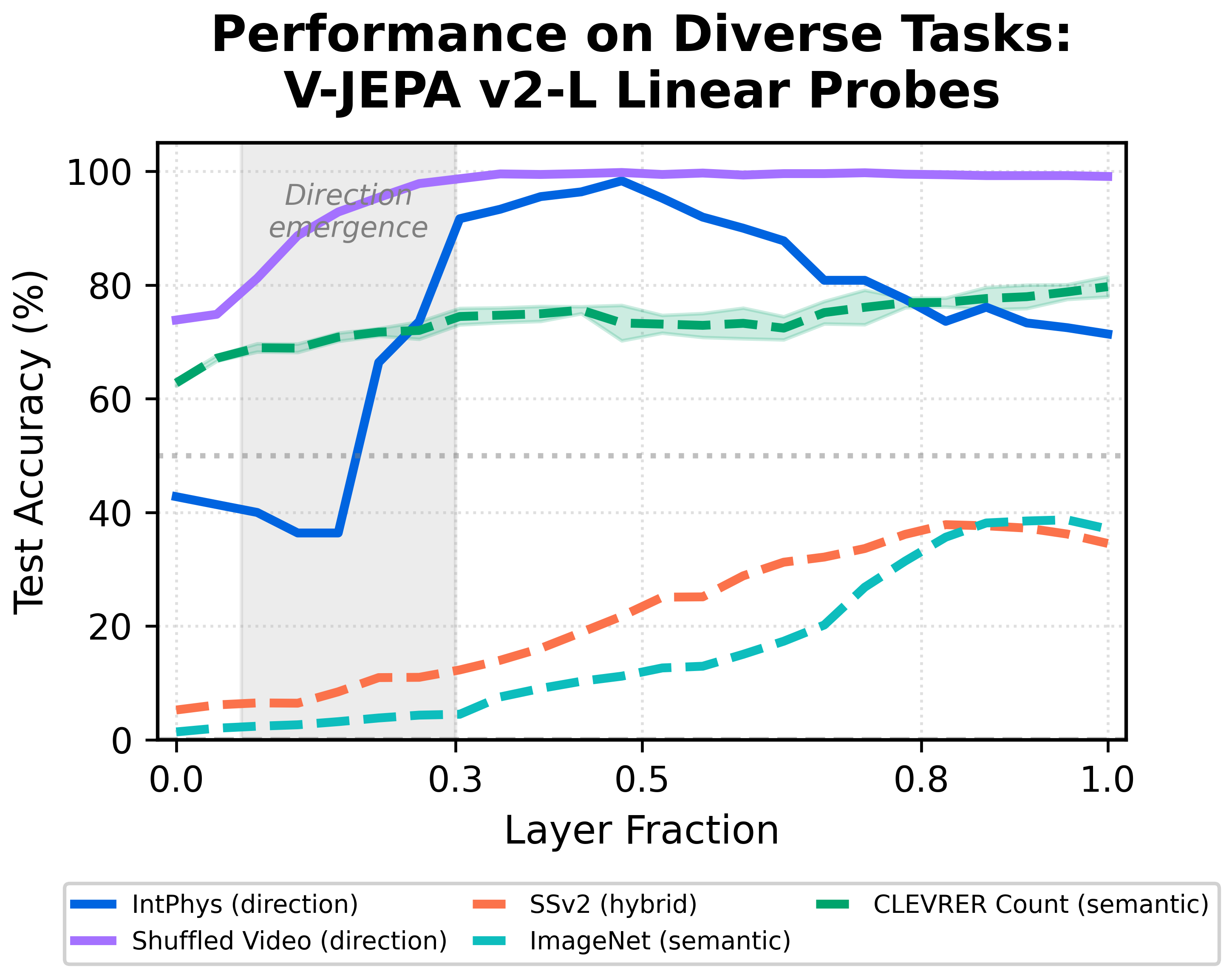
Hypothesis 1: The intuitive physics and direction task reflect a generic depth-dependent effect that applies to all tasks equally.
Result: False. The Physics Emergence Zone is unique to tasks that require spatiotemporal processing across many frames.
We repeat the layerwise probing procedure on several control tasks: CLEVRER object counting, ImageNet classification, Something-Something-v2 (SSv2), and shuffled vs. non-shuffled video discrimination.
Although CLEVRER counting and SSv2 operate on videos, they can often be solved using only a few frames. In contrast, both intuitive physics and shuffled-video discrimination require global temporal coherence.
Consistent with this distinction, the Physics Emergence Zone appears only for tasks that depend on multi-frame temporal structure. Tasks solvable from static or short-range cues do not show the same emergence pattern.
Hypothesis 2: There is a shared feature space between the two tasks that reflects compositional reuse between tasks or shared features underpinning both tasks.
Result: False. The subspaces are close to orthogonal, reflecting dataset-specific latent space features for these two tasks instead of general shared features.
We test whether intuitive physics and direction occupy overlapping subspaces, which would suggest either compositional reuse or shared latent features. Such overlap would resemble physics simulators, where a shared set of underlying variables generates multiple behaviors.
Instead, we find minimal geometric overlap. Principal angles between IntPhys and motion subspaces range from 69° to 83°, with direction closer to IntPhys (≈69°) than speed (≈81°). Projection overlap is low: only 7–13% of the IntPhys subspace projects onto direction and <3% onto speed, values indistinguishable from random projections (Björck & Golub, 1973).
Despite becoming decodable at the same depth, the two capabilities therefore occupy nearly orthogonal representational subspaces, ruling out shared latent-variable explanations.
Hypothesis 3: The two tasks share circuit-level machinery.
Result: True. Local attention in the Physics Emergence Zone underpins spatiotemporal processing for both tasks.
Although the tasks do not share representational space, their synchronized emergence suggests a shared computational mechanism. Since attention heads mediate spatiotemporal integration in video transformers, we analyze attention locality across layers.
Outside the Physics Emergence Zone, attention profiles are relatively homogeneous. Within the zone, however, a distinct population of spatiotemporally local heads appears alongside long-range heads, producing a sharp increase in attention diversity.
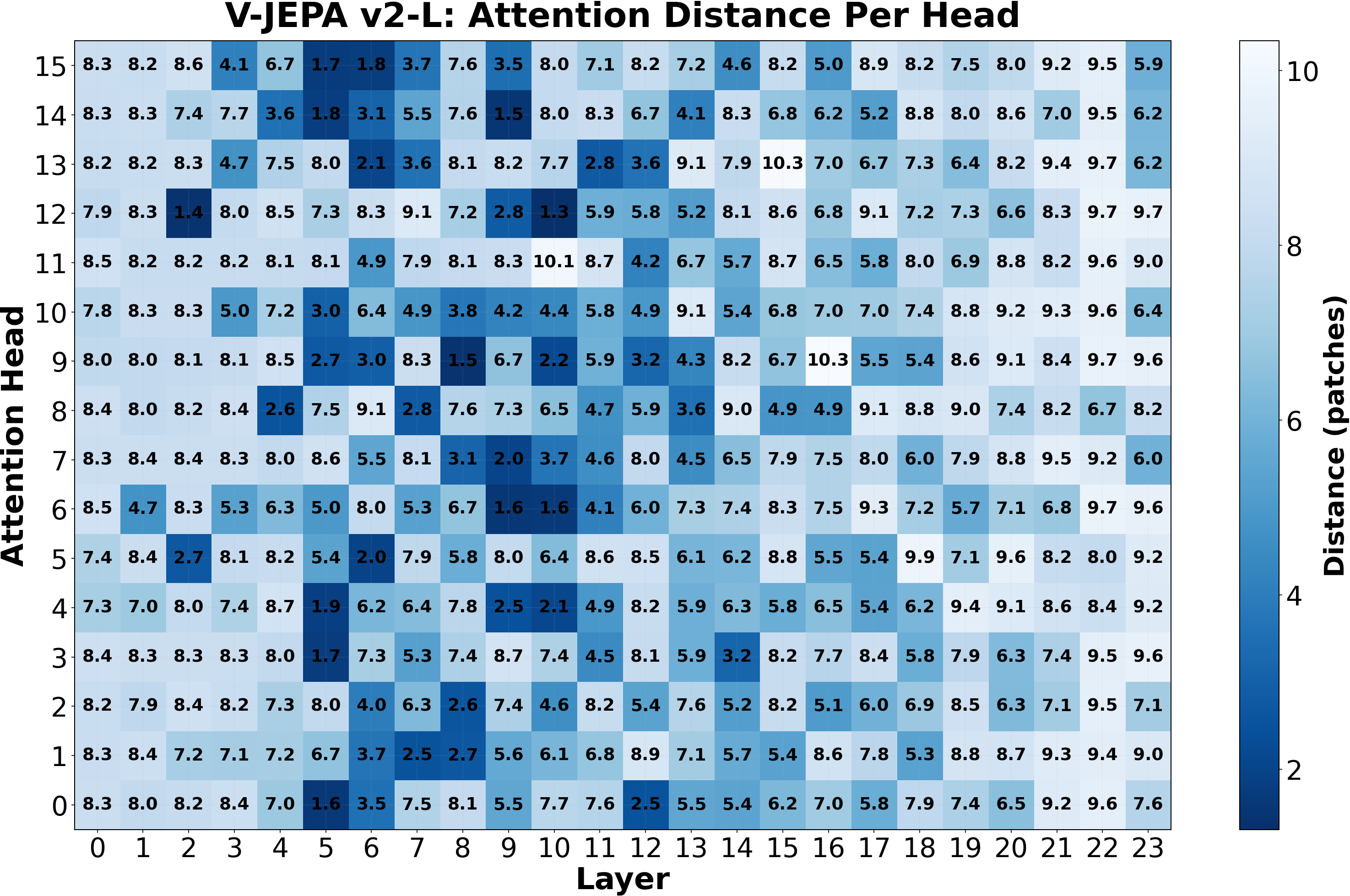
We then test causality by selectively suppressing local attention only within this region. This targeted intervention causes large performance drops on both intuitive physics and direction decoding, while leaving ImageNet classification largely unchanged.
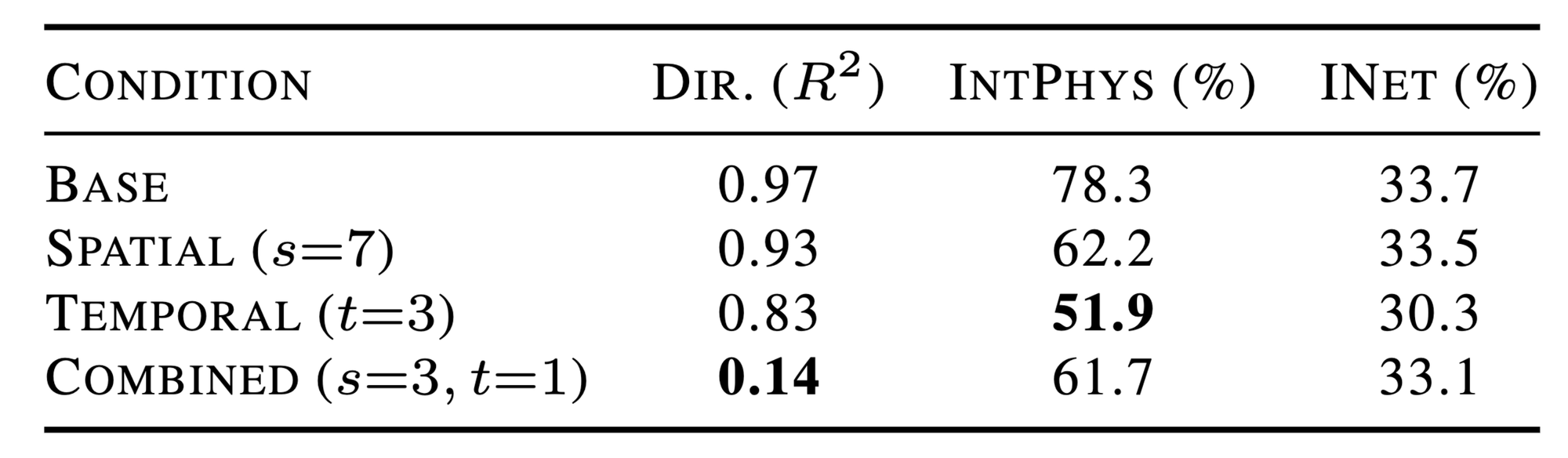
Our results identify a shared computational mechanism at the Physics Emergence Zone that supports the intuitive physics and motion direction tasks without requiring shared representational subspaces.
It should be noted that our analysis focuses on coarse spatiotemporal reasoning– other physics-related dynamics, such as contact dynamics, may rely on additional mechanisms not examined here.
Direction gets globalized patch-wise at the Physics Emergence Zone.
So far, we have examined the Physics Emergence Zone from the perspective of layers and attention heads. We now shift to a patch-level view to understand how direction information is distributed spatially across the frame.
In early layers, direction-related information is already present, but it is context-dependent and spatially unstable. For a given video, some patches may contain enough local cues to decode direction. However, these patches do not generalize across videos — the spatial location that is informative in one clip is not reliably informative in another. In other words, direction is encoded in a fragmented, video-specific manner.
At the Physics Emergence Zone, this changes qualitatively. Direction information becomes distributionally global: any patch, regardless of its spatial location or whether it contains the ball itself, carries sufficient information to decode direction across videos. As a result, per-patch probe performance rises sharply at this transition, while mean-pooled performance improves more gradually:
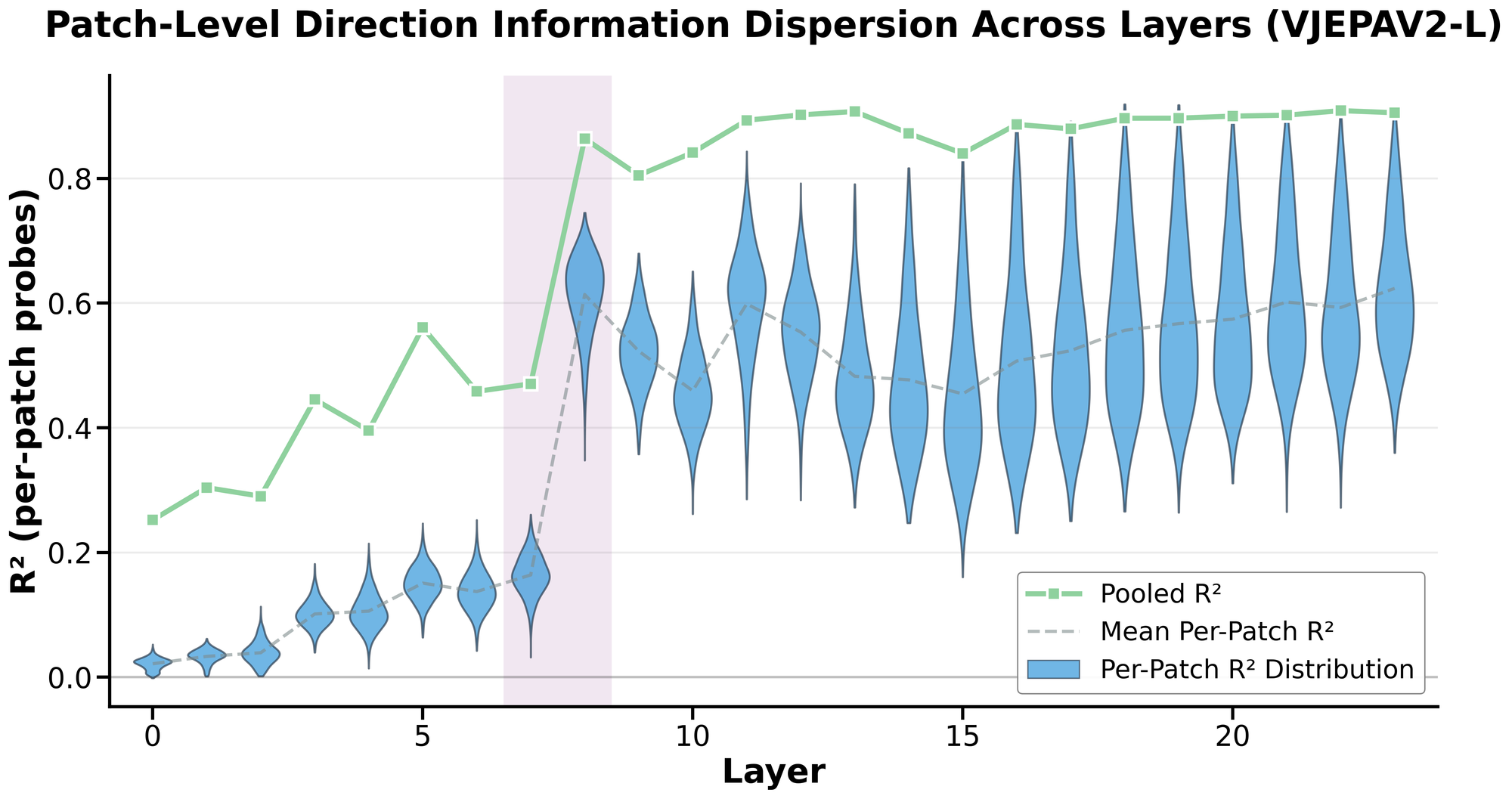
We can also visualize this transition directly using spatiotemporal heatmaps:
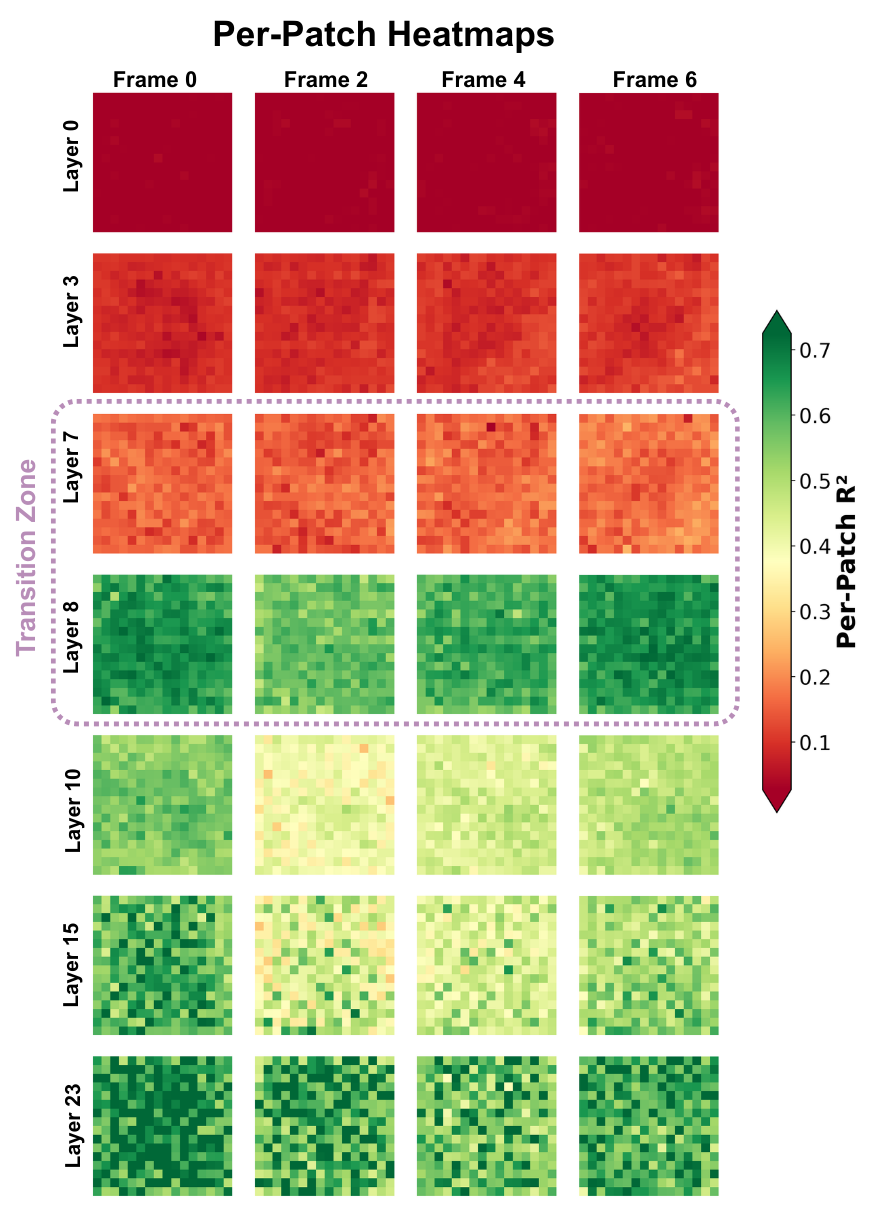
This local-to-global shift is reminiscent of the V1 → MT hierarchy in biological vision, where motion signals begin spatially localized and become increasingly pooled to yield position-invariant direction selectivity (Pasternak & Tadin, 2020; Born & Bradley, 2005).
If video world models behaved like classical physics engines, we might expect direction to reside in compact, localized variables. Instead, we find that direction is represented globally across the scene. Since V-JEPA 2 is not trained with registers, future architectures may produce more spatially factorized representations.
Direction neurons form a ring-shaped population code at the Physics Emergence Zone.
So far, we have examined the Physics Emergence Zone from the perspective of attention heads and patches. But what is happening to the MLP neurons? Are they aligning with clean features that are relevant to our physics tasks?
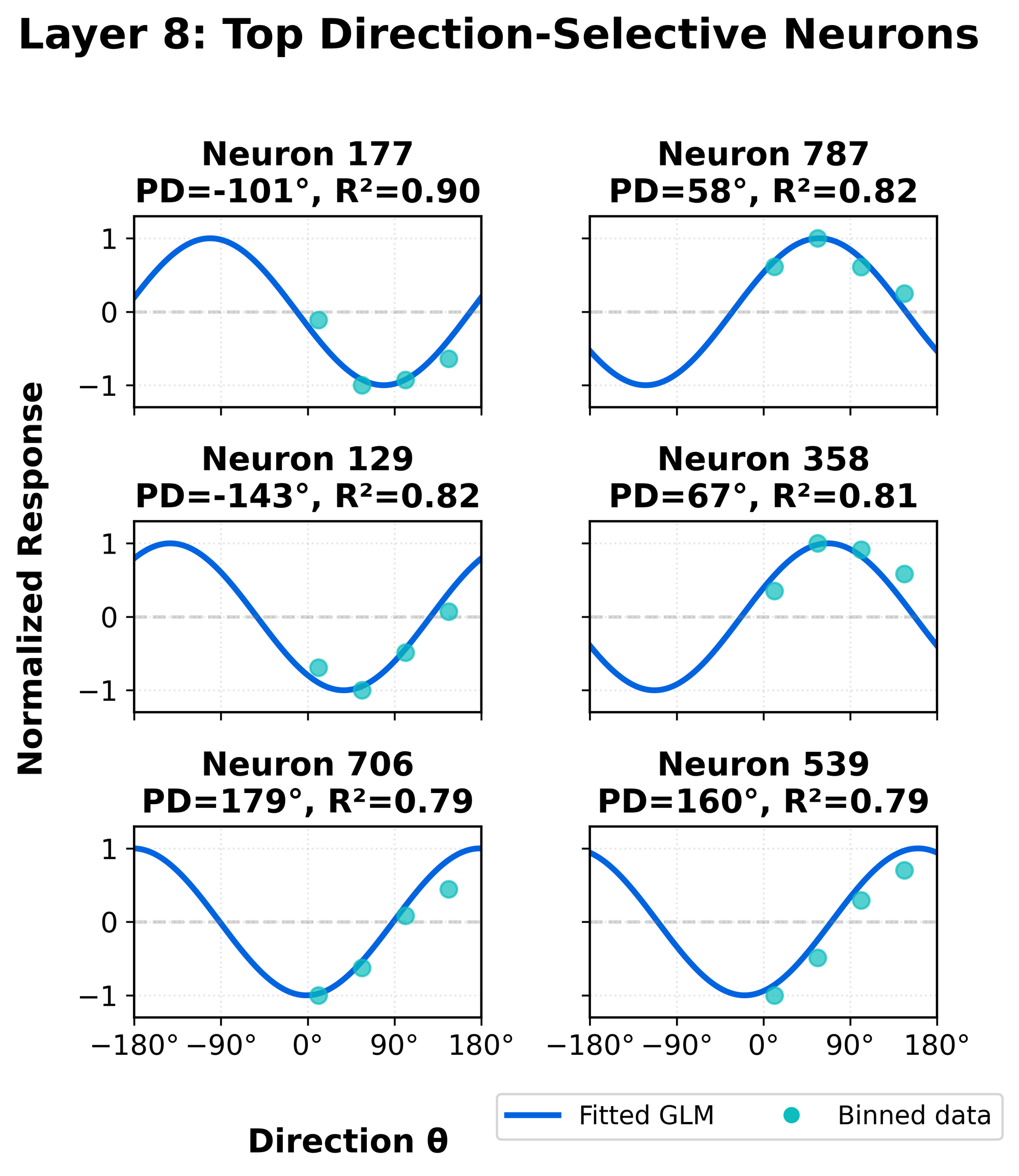
Interestingly, we find that the MLP (fc1 and fc2) neurons specialize beautifully for direction selectivity, tiling the full angular space with a circular population code! We were pretty excited by this result, as it's something that neuroscientists have long theorized about (Pasternak & Tadin, 2020; Born & Bradley, 2005), but not shown empirically due to the difficulty of measuring neurons in the brain:
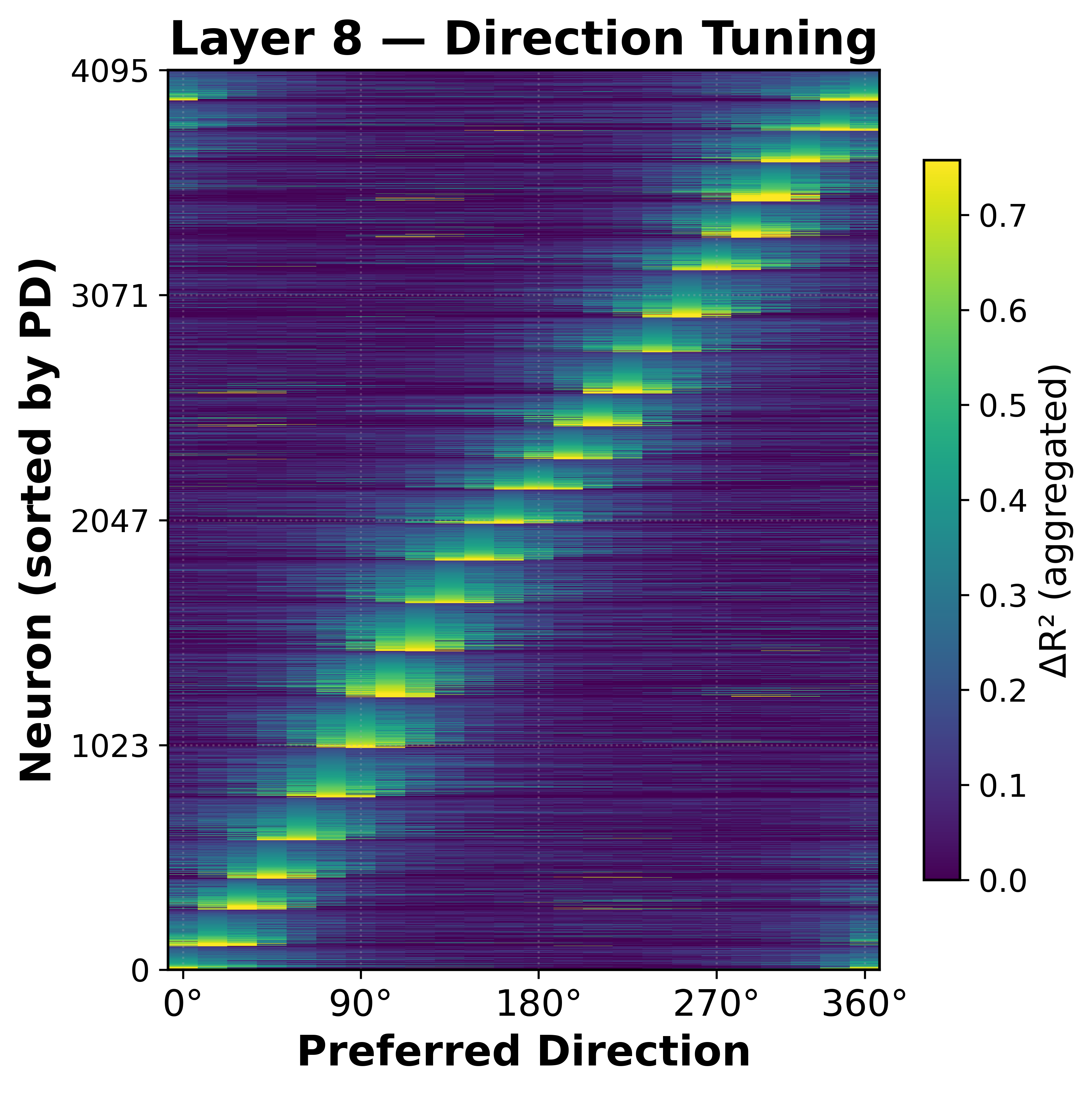
To quantify this, we fit per-neuron generalized linear models (GLMs) predicting neuron activity from the ground-truth motion direction using sine and cosine features:
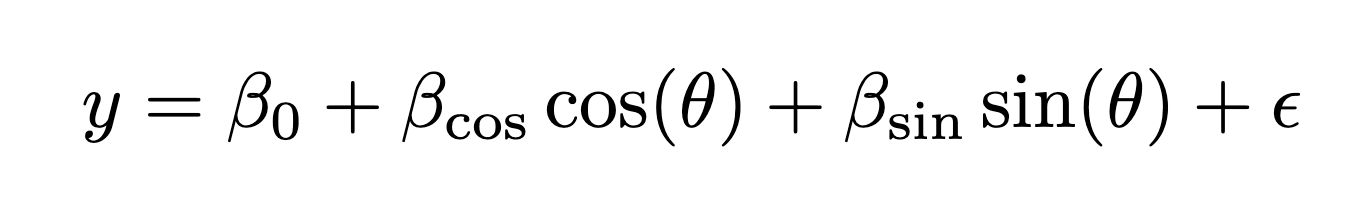
For each V-JEPA 2 MLP neuron of that layer, we fit a GLM that predicts neuron activity from the ball’s direction using sine and cosine features. That neuron’s preferred direction is then given by the angle of the fitted coefficient vector, computed as arctan2(β_sin, β_cos). The preferred directions, colored by R^2, are then visualized in the sorted heatmap above. Full details of our methodology are in the Appendix of our preprint.
When examining GLMs fitted at the end of the Physics Emergence Zone, we observe smooth direction tuning curves, consistent with classical neurophysiological results (Sarma, 2013; Albright, 1984):
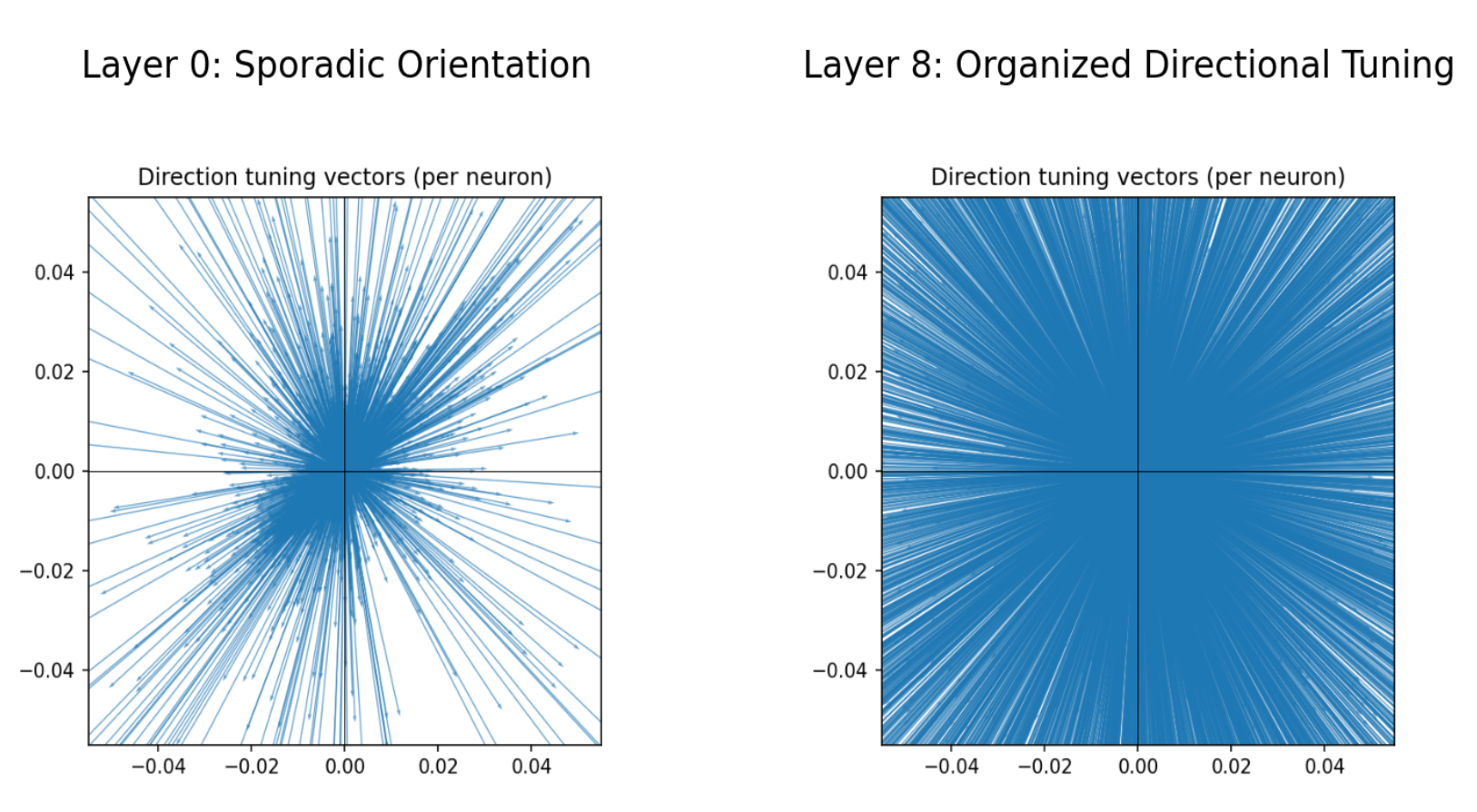
Further, we plot the preferred directions weighted by direction tuning gain (the amplitude of the parameters), we see that circular direction tuning is disorganized in the early layers of the network (Layer 0), but forms a clear organization at the Physics Emergence Zone (Layer 8):
As a control, we were curious if the MLP neurons would also specialize for speed. We don't see the same clear circular tuning.
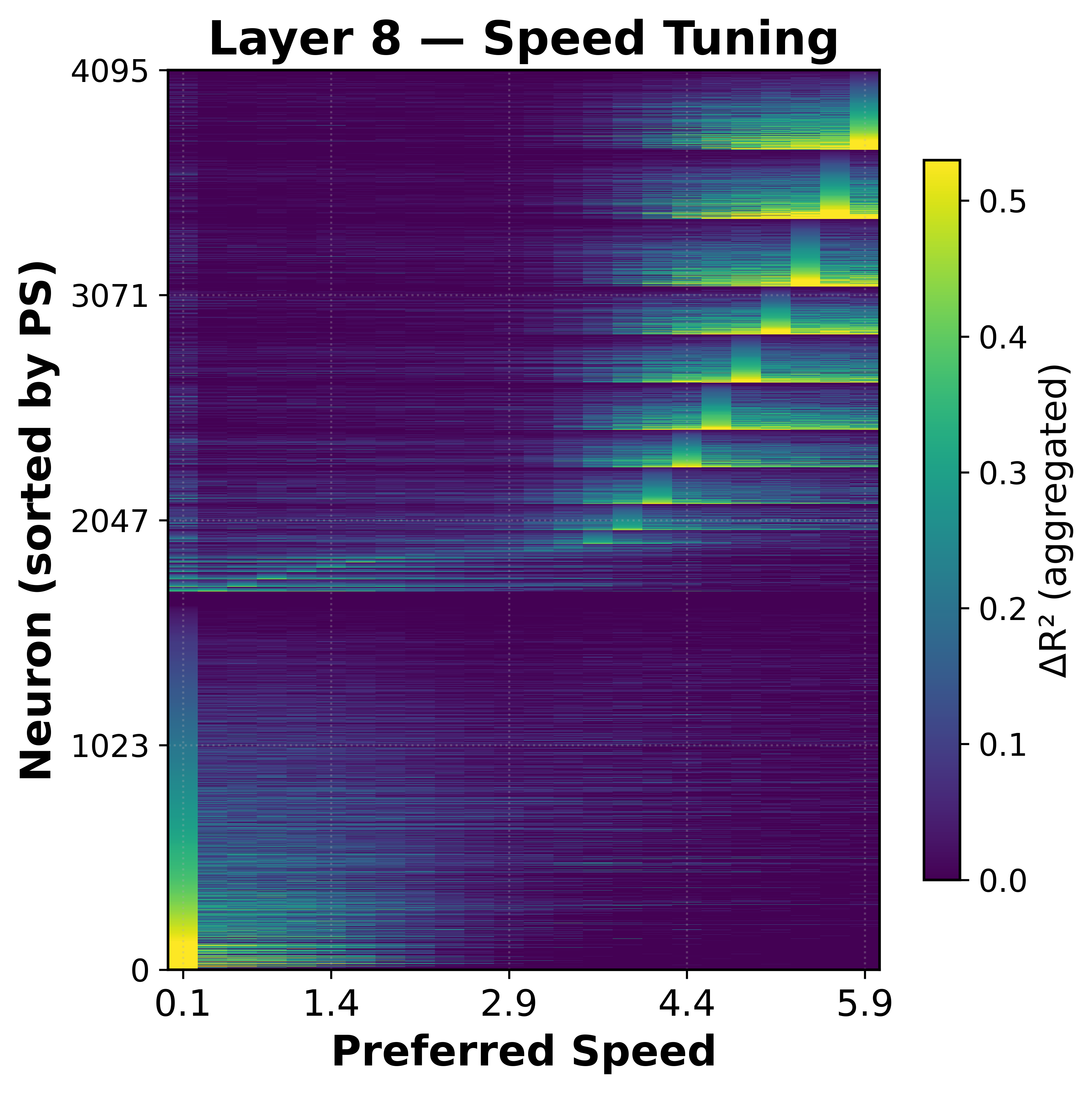
While some speed selectivity appears at higher values, the effect is weaker (R^2 ≈ 0.5) compared to direction (R^2 ≈ 0.8), suggesting that circular population coding is specific to direction.
High-dimensional physics representation and steering
Steering physics variables requires many feature dimensions
A key goal in interpretability is not only to decode information from representations, but to causally intervene on them. If a representation truly encodes a physical variable, we should be able to manipulate that representation and observe predictable changes in the model’s behavior.
We therefore attempted to steer motion direction using the circular structure observed in MLP neurons. Surprisingly, directly manipulating this unit-circle representation had little effect on the model’s internal state. The neurons appeared to be readable but not writable — they reflected direction information but did not constitute the causal locus of the representation.
This suggested that the circular tuning we observed was only a low-dimensional projection of a much richer representation.
Physics variables live in a high-dimensional subspace
To estimate the intrinsic dimensionality of motion representations, we iteratively trained linear probes, orthogonalized each probe direction, and retrained on the residual representation until performance dropped to chance.
Across tasks, we find that physics-related variables occupy high-dimensional subspaces:
- Possible vs. impossible discrimination: ~20 dimensions
- Direction decoding: ~40–50 dimensions at the emergence zone
- Direction near output layers: up to ~80 dimensions
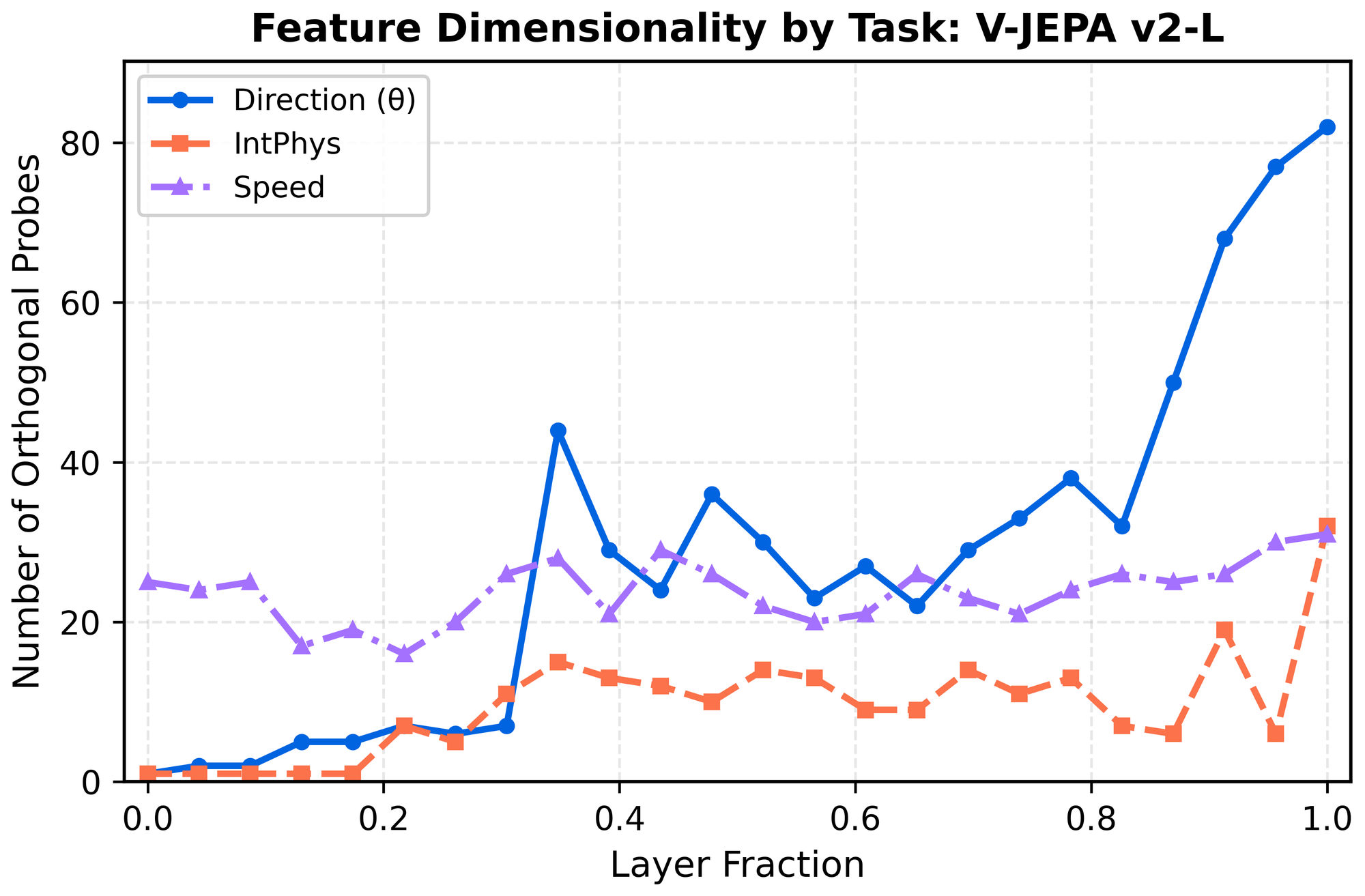
Interestingly, plotting the iterative probe accuracy for direction reveals that its representation has a curious structure! We see a "sawtooth" pattern across successive orthogonalizations, consistent with direction being encoded via approximately sinusoidal feature pairs (e.g., sine–cosine components). You can almost think of this as ~60 overlapping unit circles all encoding direction at once!
Even stranger, for each probe pair the second probe tends to latch onto the complementary cosine component (which by itself can no longer faithfully encode direction), rather than moving on to a new independent direction. This produces the jagged accuracy curve shown below.
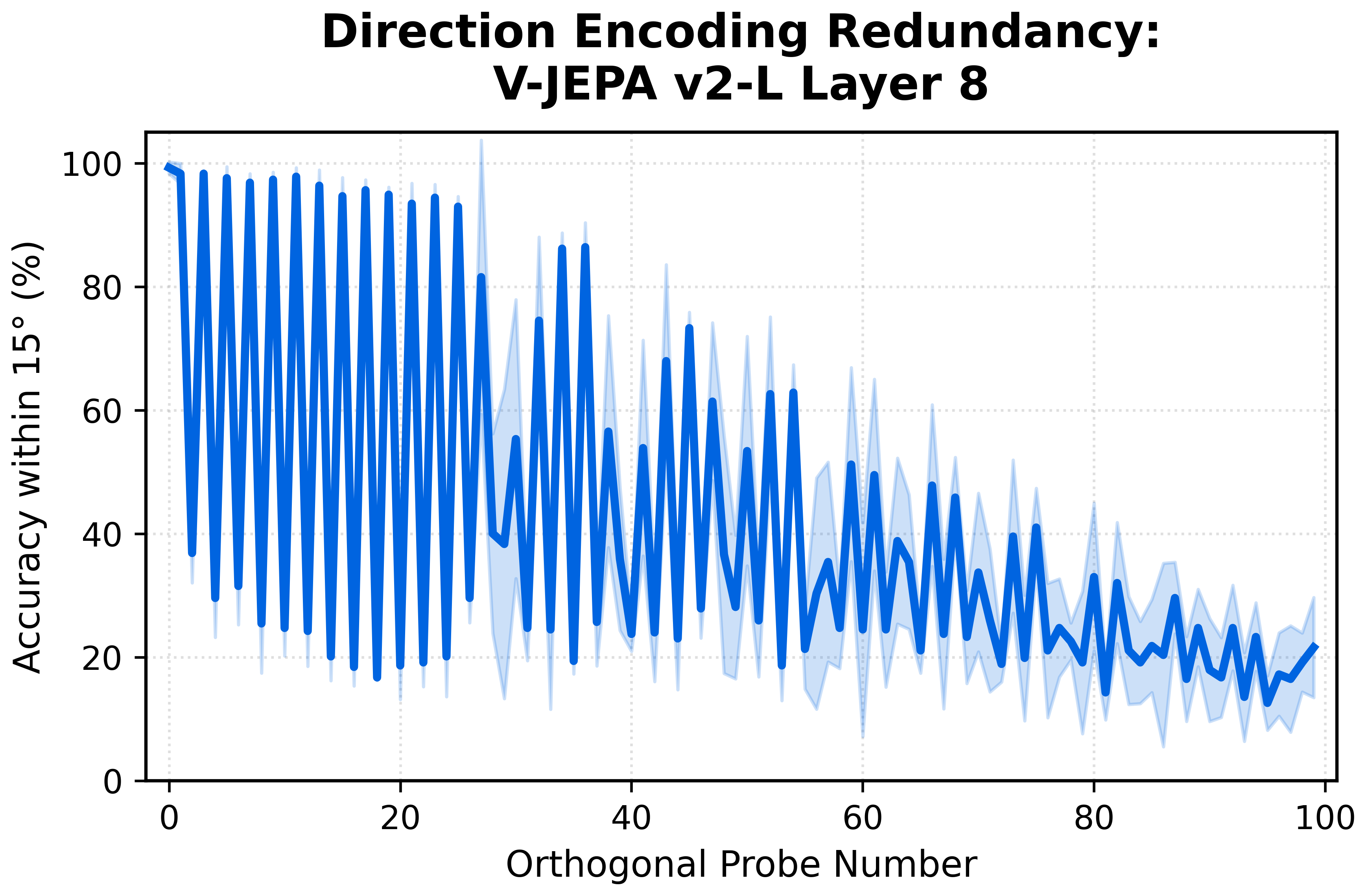
We do not yet have a definitive explanation for this behavior. The probes appear to preferentially recover complementary quadrature components of the representation, rather than discovering entirely new independent directions. This suggests that the representation may be organized around a harmonic basis rather than a set of independent feature axes.
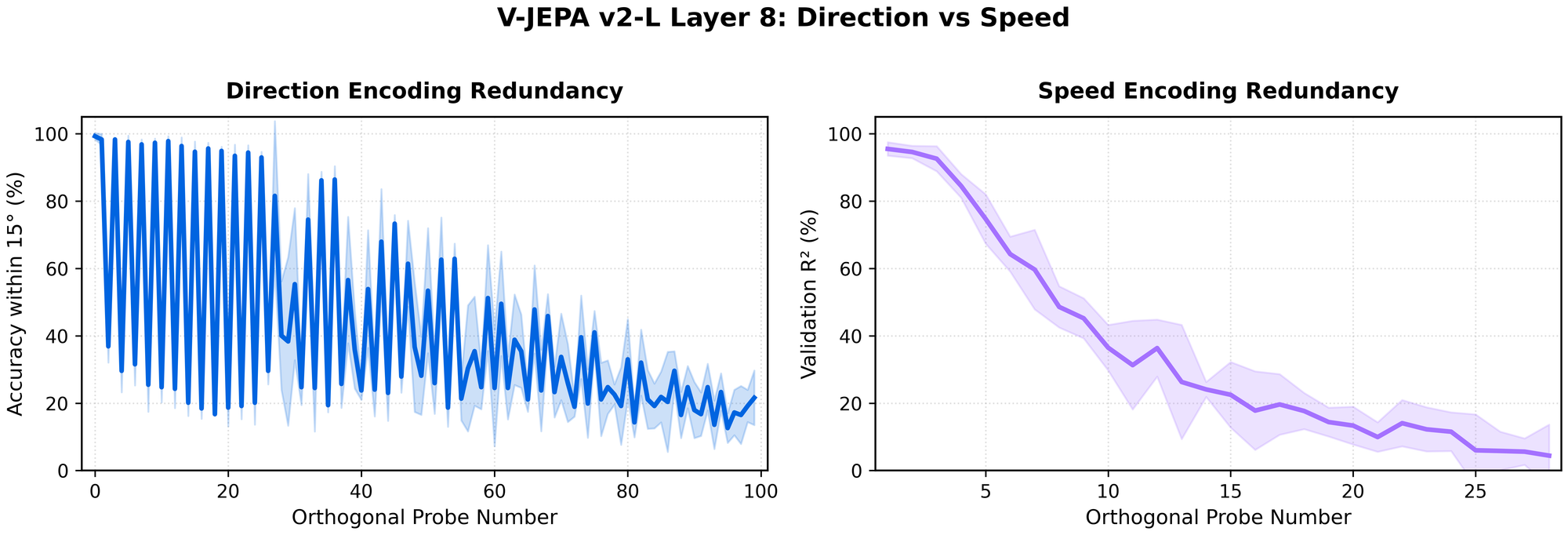
Coordinated steering in high dimensions
Activation steering here means projecting activations into a learned high-dimensional direction subspace, replacing those coordinates with ones corresponding to a target angle, and reconstructing the activations.
Unlike single-vector steering (which moves activations along one axis), this method solves for a target within a multi-dimensional subspace built from many orthogonal probes, enabling coordinated control across many directions at once.
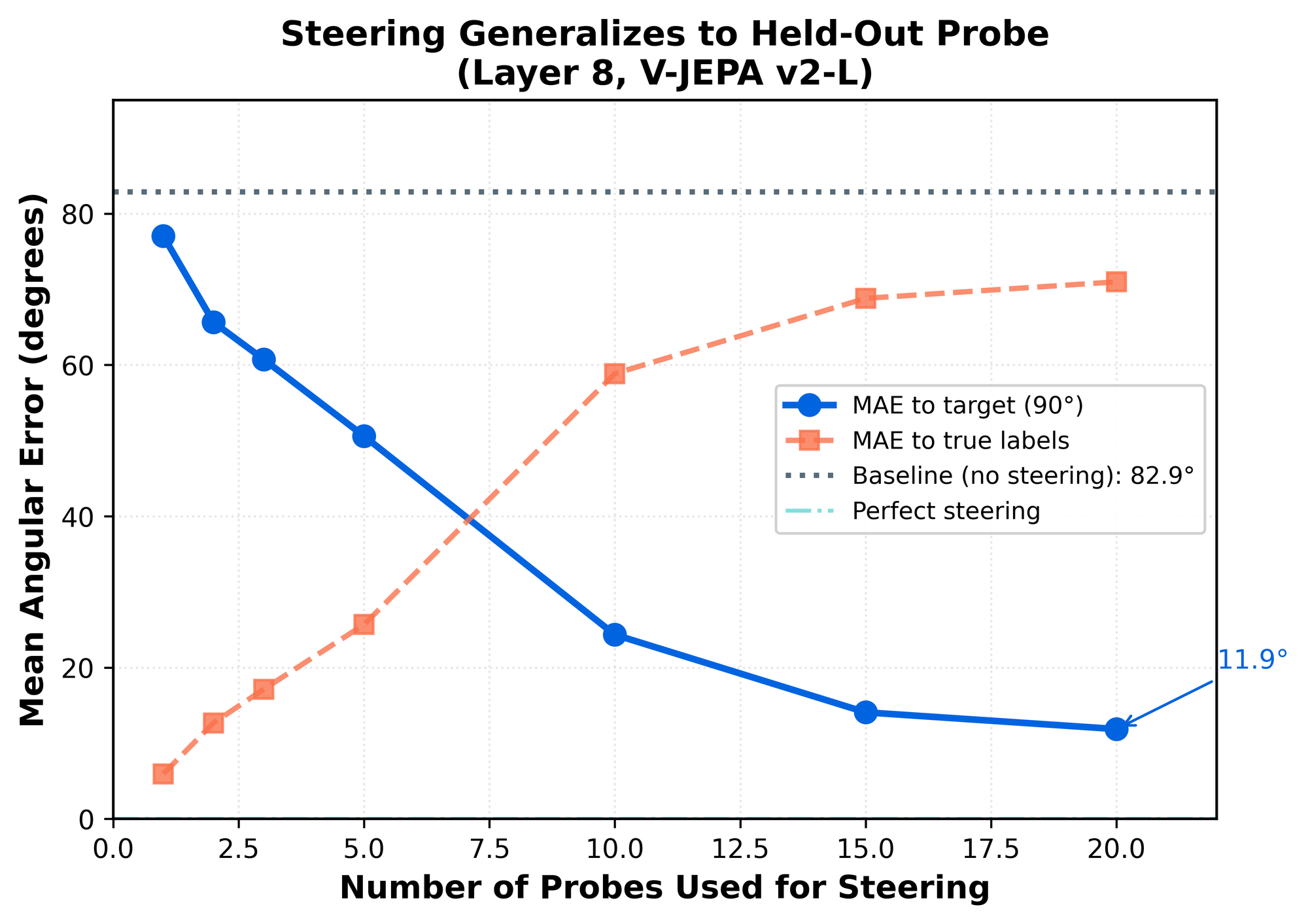
This result suggests that physical variables in video encoders are not stored as compact, single-axis latents, but as high-dimensional representations. Understanding this structure is likely essential for any attempt to control or manipulate model behavior.
It remains an open question whether other physical variables — such as shape, color, or contact dynamics — exhibit similar dimensionality, and whether more efficient steering methods can recover the same control with fewer probes.
What are the implications of our results?
Our experiments show that physical variables inside video encoders emerge as structured representations rather than compact symbolic states. This makes physical reasoning in these systems feel less like a mysterious emergent capability and more like something we can now study as a concrete computational process! In particular, motion direction appears as a coherent population code embedded in a high-dimensional subspace that becomes accessible at a specific depth of the network.
For researchers, this provides concrete evidence that physical reasoning in video models has identifiable computational structure rather than being an opaque emergent capability.
For builders and investors, it suggests something equally important: world models may not remain black boxes. Instead, they may expose internal variables that can be measured, interpreted, and eventually controlled — a key prerequisite for turning foundation models into reliable, programmable systems.
We do not claim that current models are full simulators or reliable safety infrastructure. Rather, the results demonstrate that meaningful physical structure already exists inside their representations, indicating a tractable path toward tools that make these systems more observable, controllable, and ultimately more useful in real-world settings.
We discuss some use cases below:
Auditing physical systems for reliability
One of our central findings is that physical reasoning signals — such as motion direction — emerge at predictable depths and are supported by identifiable mechanisms, including localized spatiotemporal attention. This suggests that failures in physical reasoning may correspond to measurable shifts in these internal representations, providing a concrete substrate for future diagnostic tooling.
Early interpretability research in language models has already shown that inspecting internal states can reveal phenomena such as sycophancy, deception, hallucinations, and unfaithful chain-of-thought (Lindsey et al., 2025; Zhao et al., 2025). As models increasingly act in physical environments, similar failure modes will have more immediate real-world consequences.
Understanding the internals of world models may be useful for safety, as with the case of the dishwasher robot that secretly does terrorist activity, as described earlier in this post. It may also be useful for auditing models for reliability, such as cases of plausible and implausible physical generations. For example, a model that predicts faulty physics can be shut down early, or omit a warning signal, based on training a "latent space auditing model" on top of the activation patterns of the forward pass.
While such systems remain future work, our results indicate that the representational scaffolding required for them is already present. The long-term implication is a shift from evaluating models solely through outputs to analyzing them through their internal state– a paradigm change in how complex AI systems are debugged and trusted.
Learning scientific simulators in an unsupervised way
The word "world model" has been thrown around a lot, especially in Silicon Valley– often used interchangeably with generative environments, physical plausibility, or embodied robotic control. We’d like to propose a more concrete framing: the foundation model itself is already a world model, and interpretability is a tool for decoding its latent structure.
Currently, across scientific domains such as climate science, materials science, biology, and fluid dynamics, researchers rely on hand-crafted simulators to model system dynamics. The promise of interpretability in world models is different: rather than specifying equations a priori, we can attempt to uncover the latent variables that the model has learned from data and study how they generate behavior.
In our controlled physics setting, a natural gold standard would be the ability to steer the direction and speed subspaces to precisely control the ball — analogous to turning direction and velocity “knobs” in a traditional simulator. While this remains far from current capabilities, it illustrates a concrete path from representation analysis to controllable modeling.
This paradigm of data-driven scientific modeling could be particularly valuable in domains where labeled data is scarce or the governing dynamics are only partially understood, offering a complementary approach to classical simulation.
Informing debates in cognitive science and neuroscience
Many schools of thought have proposed using neural networks as an “artificial brain” or experimental petri dish for de-risking real-world experiments in silico (Richards, 2019). We’re excited by the possibility of doing something along these lines here.
Several patterns we observe — including the shift from spatially local to global direction representations and the emergence of circular population codes — echo motifs reported in biological vision. In particular, our results show a concrete computational example where physics-relevant variables arise through distributed population activity rather than compact symbolic states.
More broadly, it remains unclear how the brain represents physical dynamics or how faithfully the mind simulates the physical world. Our findings do not cleanly resolve these questions, but they provide a mechanistic reference point: physical reasoning can emerge from structured yet high-dimensional representations that sit between classical “physics engine” accounts and purely task-specific heuristics.
Studying video world models therefore offers a controlled setting in which these longstanding questions can be explored with unusually direct access to internal representations, complementing behavioral and neural evidence.
Closing thoughts
Our results suggest that physical reasoning in video models is not merely a behavioral capability but a property of structured internal representations that emerge at specific depths of the network.
In the near term, this provides a concrete foundation for studying and improving the interpretability of world models. While much remains to be understood, the fact that these structures are already visible suggests that interpretability of world models may evolve from a diagnostic tool into a design principle.
In the longer term, it points toward a future where foundation models are not only powerful predictors, but systems whose internal variables can be understood, monitored, and ultimately shaped– enabling new forms of reliable AI infrastructure for the physical world and data-driven scientific discovery.
For a full description of our methods, please see our arXiv paper here.
--
If you reference our work, please cite our arXiv paper:
@misc{joseph2026interpretingphysicsvideoworld,
title={Interpreting Physics in Video World Models},
author={Sonia Joseph and Quentin Garrido and Randall Balestriero and Matthew Kowal and Thomas Fel and Shahab Bakhtiari and Blake Richards and Mike Rabbat},
year={2026},
eprint={2602.07050},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.07050},
}
--
Acknowledgements
Thank you to the JEPA team for the continuous feedback and discussions, including Florian Bordes, Mido Assran, Nicolas Ballas, Amir Bar, and Yann LeCun.
Thank you to the LiNC Lab members for the feedback as well, including Aidan Sirbu, Dane Malenfant, and Colin Bredenberg.
Finally, thank you to Christina Last for the discussions about physics simulators and to Ophira Horwitz for the discussions about incorrect physics in dreams.
Member discussion